Linktipps
Kommt mit uns ins Gespräch!

Unser Gast: Markus Hövener
Markus Hövener – einer von vielen Top-Interviewgästen in unserem Podcast
|
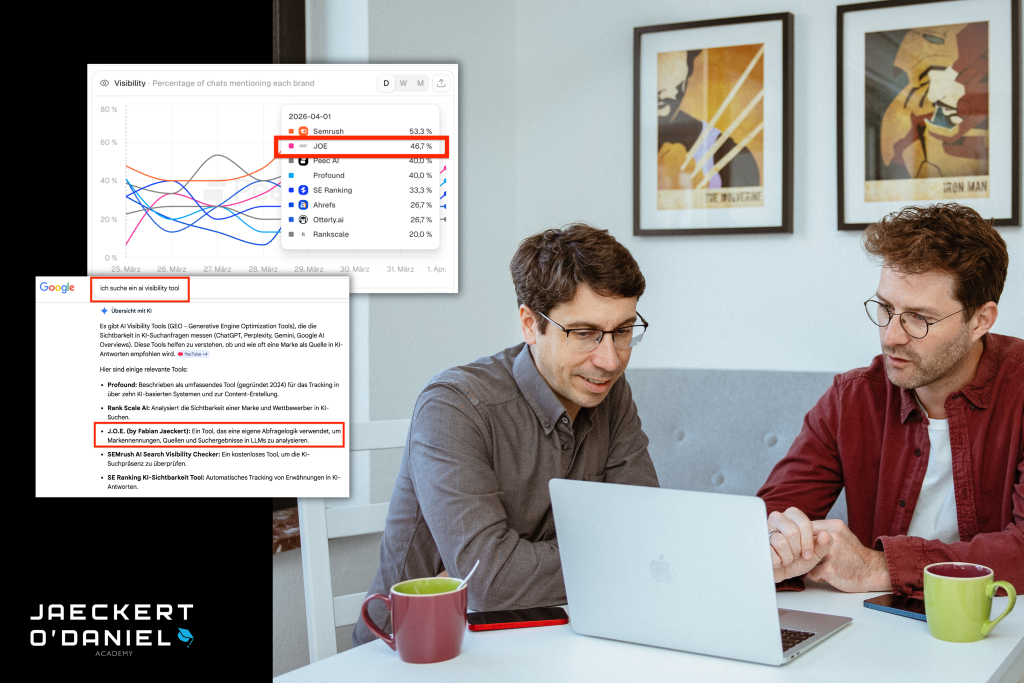
SEO Tools Spezialtools vs Allrounder |

|
B2B Online Marketing: Herausforderungen 2019 Unser Interview mit Markus Hövener über Customer Journeys von Drei-Millionen-Maschinen |

|
1 Millionen Nutzer im Monat - mit der richtigen Content Strategie Jan Brakebusch von Liebscher & Bracht erklärt, wie er mit seinem Team da hingekommen ist. |

|
Relaunch & SEO: Wie ihr den Totalschaden verhindert Wo liegen die Chancen und Gefahren? |

|
Content Audit und SEO: Wie analysierst du 500 Unterseiten? Warum viele keinen Überblick haben - und wie wir vorgehen. |
|
|
Was ist das beste CMS für SEO? Spoiler: Für SEO muss man nicht sein System wechseln. Worauf es wirklich ankommt. |

|
Wie man internationale SEO-Strategien entwickelt: Interview mit Matthäus Michalik Andere Länder, andere Sitten. Mit entsprechenden Folgen für SEO und Content. |

|
Warum der Graue Index in der Search Console ein SEO-Hebel ist Technisches SEO ist und bleibt wichtig. |